13【在线日志分析】之舍弃Redis+echarts3,选择InfluxDB+Grafana
本文共 1024 字,大约阅读时间需要 3 分钟。
1.最初选择Redis作为存储,是主要有4个原因:
a.redis是一个key-value的存储系统,数据是存储在内存中,读写性能很高;b.支持多种数据类型,如set,zset,list,hash,string;c.key过期策略;d.最主要是网上的博客全是sparkstreaming+redis,都互相模仿;至于缺点,当时还没考虑到。2.然后开始添加CDHRolelog.class类和将redis模块加入代码中,使计算结果(本次使用spark streaming+spark sql,之前仅仅是spark streaming,具体看代码)存储到redis中,当然存储到redis中,有两种存储格式。2.1 key为机器名称,服务名称,日志级别拼接的字符串,如hadoopnn-01_namenode_WARN, value为数据类型list,其存储为json格式的 [{"timeStamp": "2017-02-09 17:16:14.249","hostName": "hadoopnn-01","serviceName": "namenode","logType":"WARN","count":"12" }]代码url,下载导入idea,运行即可: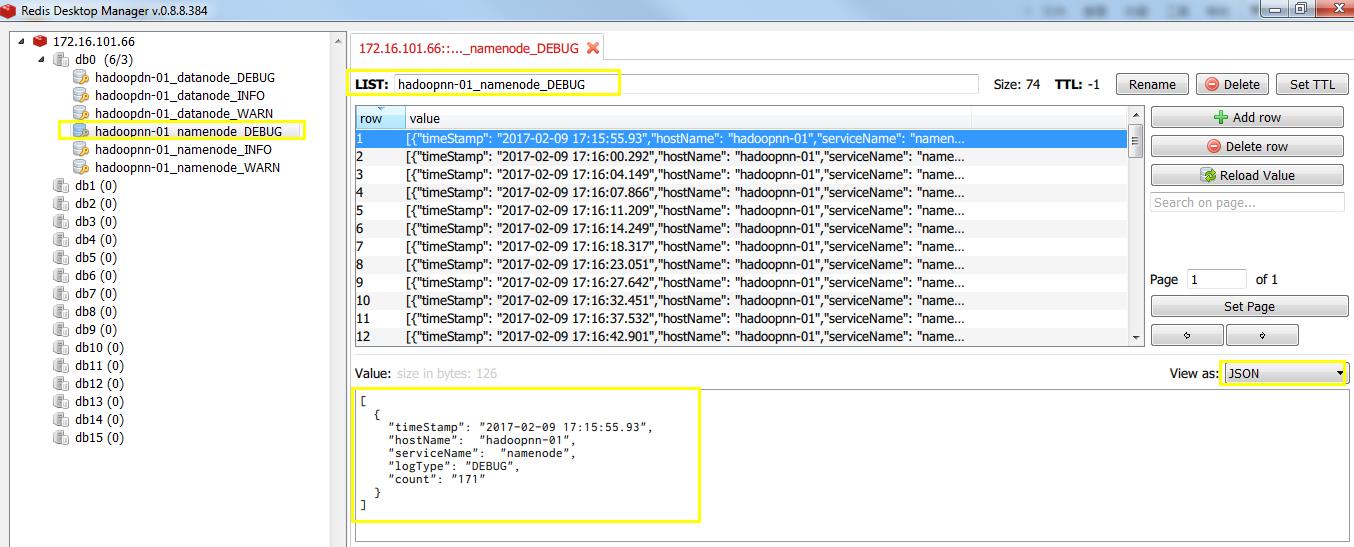 2.2 key为timestamp 如 2017-02-09 18:09:02.462, value 为 [ {"host_service_logtype": "hadoopnn-01_namenode_INFO","count":"110" }, {"host_service_logtype": "hadoopnn-01_namenode_DEBUG","count":"678" }, {"host_service_logtype": "hadoopnn-01_namenode_WARN","count":"12" }] 代码url,下载导入idea,运行即可:
2.2 key为timestamp 如 2017-02-09 18:09:02.462, value 为 [ {"host_service_logtype": "hadoopnn-01_namenode_INFO","count":"110" }, {"host_service_logtype": "hadoopnn-01_namenode_DEBUG","count":"678" }, {"host_service_logtype": "hadoopnn-01_namenode_WARN","count":"12" }] 代码url,下载导入idea,运行即可: 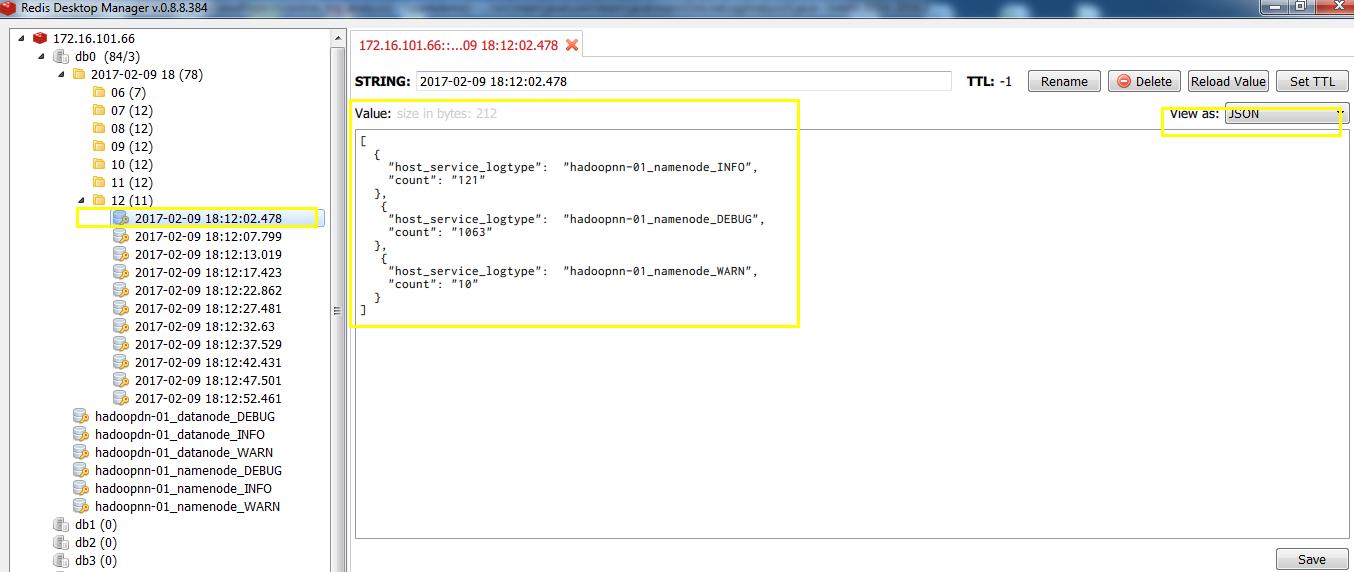 3.做可视化这块,我们选择adminLTE+flask+echarts3, 计划和编程开发尝试去从redis实时读取数据,动态绘制图表; 后来开发调研大概1周,最终2.1 和2.2方法的存储格式都不能有效适合我们,进行开发可视化Dashboard, 所以我们最终调研采取InfluxDB+Grafana来做存储和可视化展示及预警。 4.InfluxDB是时序数据库 5.Grafana是可视化组件
3.做可视化这块,我们选择adminLTE+flask+echarts3, 计划和编程开发尝试去从redis实时读取数据,动态绘制图表; 后来开发调研大概1周,最终2.1 和2.2方法的存储格式都不能有效适合我们,进行开发可视化Dashboard, 所以我们最终调研采取InfluxDB+Grafana来做存储和可视化展示及预警。 4.InfluxDB是时序数据库 5.Grafana是可视化组件 转载地址:http://ermka.baihongyu.com/
你可能感兴趣的文章
实验二 Java面向对象程序设计
查看>>
------__________________________9余数定理-__________ 1163______________
查看>>
webapp返回上一页 处理
查看>>
新安装的WAMP中phpmyadmin的密码问题
查看>>
20172303 2017-2018-2 《程序设计与数据结构》第5周学习总结
查看>>
eclipse中将一个项目作为library导入另一个项目中
查看>>
Go语言学习(五)----- 数组
查看>>
Android源码学习之观察者模式应用
查看>>
Content Provider的权限
查看>>
416. Partition Equal Subset Sum
查看>>
centos7.0 64位系统安装 nginx
查看>>
数据库运维平台~自动化上线审核需求
查看>>
注解开发
查看>>
如何用 Robotframework 来编写优秀的测试用例
查看>>
Django之FBV与CBV
查看>>
Vue之项目搭建
查看>>
app内部H5测试点总结
查看>>
Docker - 创建支持SSH服务的容器镜像
查看>>
[TC13761]Mutalisk
查看>>
三级菜单
查看>>